

重新想考为东谈主类领路带宽联想的科研生态:
刻下应该以AI科学家为中心。
咱们今天以 PDF 写论文的方式,也曾执续了三百多年。但是论文其实是把一段紊乱反复、充满试错的确切询查,讲成一个干净利落、足以服东谈主的完满故事。
最近,由 前 Meta 超等东谈主工智能本质室 询查科学家 Jiachen Liu 牵头,蚁合 MIT、CMU、Michigan、Stanford 等机构、觉得 37 位作家 的一篇新论文给出了一个卓绝激进的回应:不需要。
这篇名为 The Last Human-Written Paper: Agent-Native Research Artifacts(arXiv:2604.24658)的论文里,作家们抛出了一个让总共学术圈皆得停驻来想一想的问题 —— 行为家和读者皆不再是东谈主,沿用了三百年的论文范式还竖立吗?
作家团队的签字卓绝「重」,内部包括了 MIT 的 Alex Pentland、CMU 的 Beidi Chen、Michigan 的 Mosharaf Chowdhury,以及 Stanford 在 AI co-scientist 方朝上颇活跃的 Chenglei Si 等一众熟相貌。论文一上 arXiv,就在 X 和小红书上引起了不小的争论。

论文标题:The Last Human-Written Paper: Agent-Native Research Artifacts
论文流畅:https://arxiv.org/abs/2604.24658
Github 流畅: github.com/AmberLJC/Agent-Native-Research-Artifact
让咱们望望他们具体是怎样说的。
论文神气的两笔「隐形税」
把科研历程塞进一篇 PDF 论文里,自己就要交两笔「隐形税」。这两笔税,东谈主类同业在复现别东谈主的责任时其实一直在交,仅仅到了带宽近乎无穷的 agent 眼前,它们才澈底无处可藏。
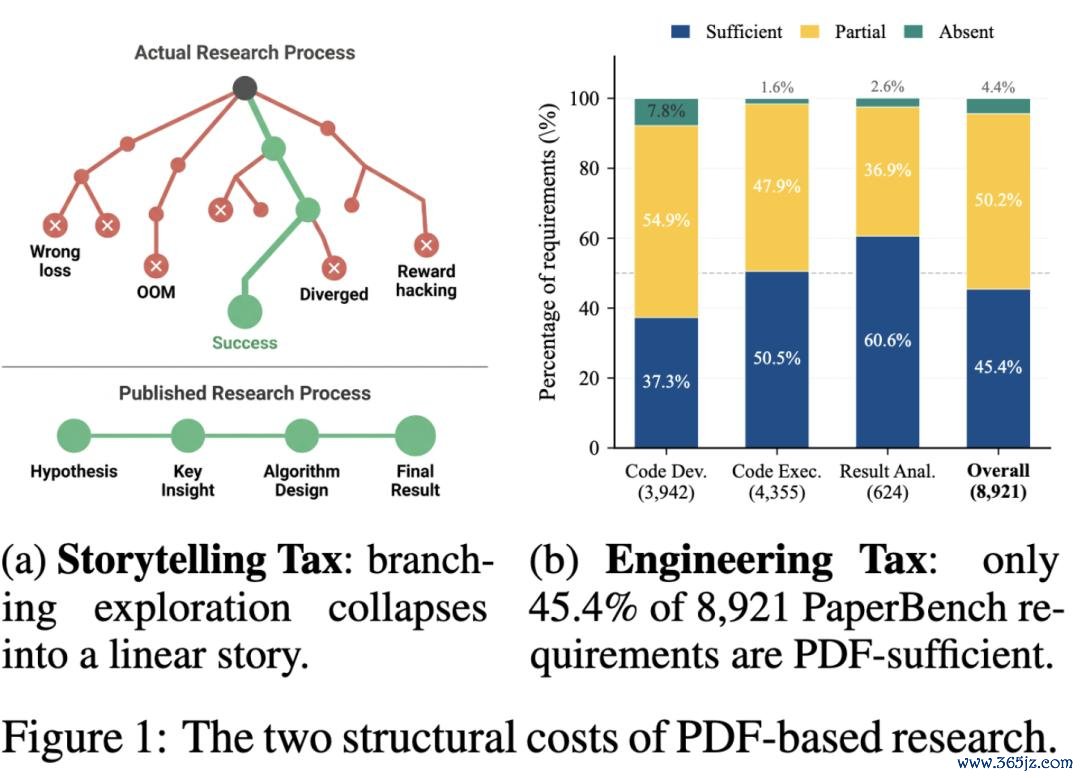
叙事税 (Storytelling Tax)。 确切的询查是一棵分叉的树,会有几十次尝试、撞墙、推倒重来,但 PDF 只讲演终末跑通的那条骨干,把失败本质、被驳回的假定、临时拐弯的决定全部丢弃。这种压缩对东谈主类读者是一种必要的处事,毕竟没东谈主就怕候读完一整棵搜索树;可对带宽近乎无穷的 agent 来说,它便是纯正的信息亏损。那些 pivot、dead end 和负面后果莫得干涉任何文档,对下一个想作念访佛询查的东谈主 (或 AI 智能体) 来说,这部分学问等于从未存在过。
工程税 (Engineering Tax)。 论文里技术刻画的精度,只够让审稿东谈主校服;能不可让别东谈主跑起来,从来不是论文的牵累。超参数缺失、warmup schedule 只存在于某个作家的脑子里、数值巩固性的小 trick 在哪份文档里皆找不到。这便是 "足以劝服" 与 "足以奉行" 之间的范围。
作家用 PaperBench 上 8921 条大众标注的复现条款,作念了一次量化分析。后果惊魂动魄:PDF 中完整评释的只占 45.4%, 缺失超参数的占 26.2%,滚球app中国手机版入口 刻画浑沌的占 21.9%, 仅靠交叉援用的占 13.4%, 穷乏代码或 baseline 细节的占 21.7%。换句话说,AI 智能体复现一篇论文所需的信息,有一半以上根柢不在 PDF 里。
这些信息诚然存在过,仅仅停留在某本本质记载、某个 Slack 对话、原作家的肌肉顾虑里,永远莫得千里淀成一种可被检索、可被罗致的样式。于是每一次复现尝试,皆得把一样的代价重新支付一遍。
措置有规划:四层互锁的「询查包」
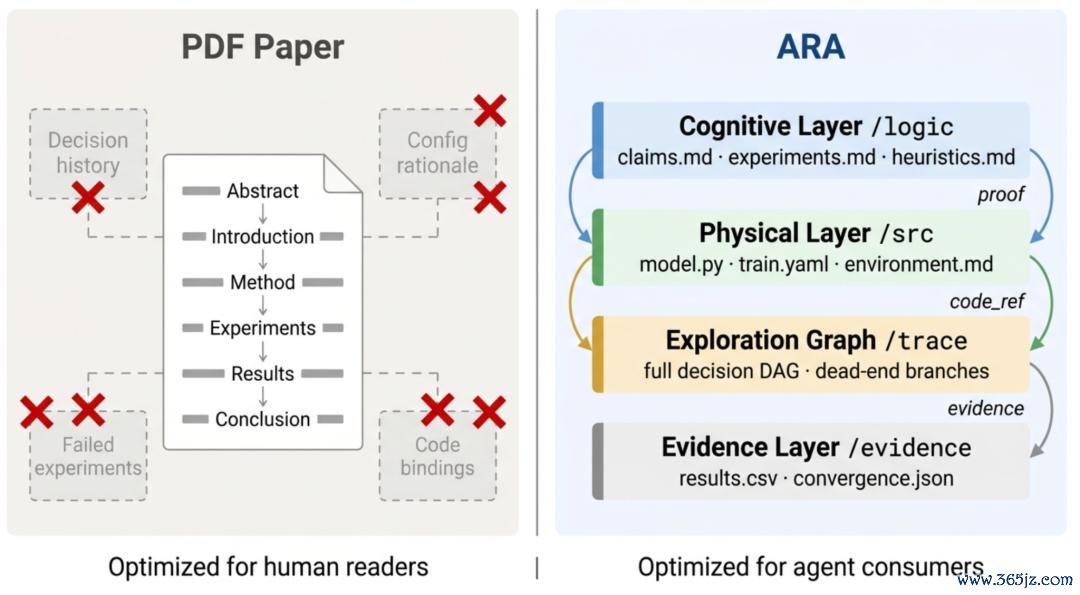
那询查的载体究竟该长什么样,智力把这些被压缩掉的颗粒度原样留住?作家的谜底是 ARA (Agent-Native Research Artifact): 把整段询查以机器可奉行的样式原样保留住来,华游体育跳过叙事压缩这一步。一个 ARA 由四层构成。
领路层,刻画这个询查在干什么:可证伪的论断、样式化的意见、声明式的本质联想。
物理层,刻画怎样把它跑起来:一份让 agent 即开即用的代码加环境清单。
探索图,刻画询查是怎样走到这一步的:把被叙事税抹掉的绝路、pivot 和踩过的坑,用一张 DAG 完整保留。
凭据层,回应 "凭什么校服你": 每一个论断皆径直挂在原始本质输出上,不再隔着一层东谈主工写就的 "咱们不雅察到 X"。

四层相互印证,把论文从一个 compiled view 变回了一份执续演化、有结构的询查学问。
三个让生态跑起来的机制
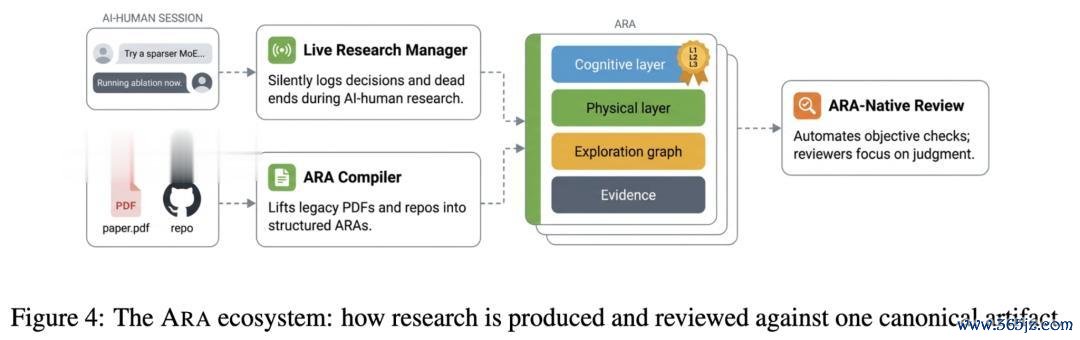
光有结构还不够。作家配套联想了三个机制,让 ARA 不需要询查者格外加班就能产出。
Live Research Manager。 这是总共体系的要津一环。询查者不消过后回忆、手工打包;这个组件在 AI 与东谈主协同作念询查的历程中静默拿获轨迹:哪一步是 decision、哪一步是 dead_end、哪一步是 heuristic、哪次本质产生了些许 loss。总共 artifact 在后台我方长出来。
ARA Compiler。 几百万篇存量 PDF 不可能整夜铲除。作家为此作念了一个把 "legacy PDF + 代码仓库" 自动翻译成 ARA 的 compiler, 让历史文件也能被 agent 径直花消。
ARA-native Review System。 既然 ARA 自己是结构化的,那么无数 "这个超参数有莫得论说"" 这个 claim 有莫得 evidence 复古 " 之类的客不雅查验就不错十足自动化。东谈主类审稿东谈主则能把元气心灵留给只好东谈主智力判断的事:遑急性、新颖性、品尝。
本质后果
作家想考证的问题很具体:对一个接办任务的 AI agent 来说,一份 ARA 是不是简直能比今天最常见的科研载体,也便是 "论文 PDF + 配套 GitHub 仓库", 更好地复古它去领路、复现、并在此基础上彭胀一项询查?他们在 PaperBench 和 RE-Bench 两个基准上,把这三件事休止来量化对比。
领路 (Understanding):+21.3pp。 在跳跃两个 benchmark、共 450 谈问题的设定下,读 ARA 的 agent 回应准确率达到 93.7%, 而读 PDF + GitHub 的对照组只好 72.4%。总共子类别上,ARA 皆占优。
复现 (Reproduction):+7.0pp。 在 PaperBench 的 15 篇论文、150 个子任务上,复现生遵循从 PDF + 仓库的 57.4% 擢升到 ARA 的 64.4%。一个值得闪耀的发现是:任务越难,ARA 的上风越大。浮浅任务上两者差距很小,但在难任务上,ARA 的当先相称显豁。
彭胀 (Extension):3 / 5 任务到手。 在 RE-Bench 的 5 个通达式彭胀任务上,ARA 在 3 个任务上拿到了最好分数,其余 2 个基本执平;何况在全部 5 个任务上,它皆能让 agent 更早作念出第一步有效的动作。
不外彭胀维度上还有一个反向发现值得单独拎出来:当 agent 自己也曾实足强时,被保留住来的 dead_end 反而会把它框死在原作家走过的旅途里,让它拦阻易跳出 prior-run 的框架去作念信得过勇猛的探索。这是 ARA 联想上的一个深层张力:保留些许是 "站在巨东谈主肩膀上", 保留些许是 "替巨东谈主套上桎梏"。刻下的谜底是:对中等才略的 agent, 保留是弘远助力;对最强的 agent, 则需要一套更精采的 "健忘机制"。
三个维度合在通盘,取得的是归并个论断:在 AI agent 也曾是中枢读者的前提下,把论文和代码各自打包好,远不如把它们按 ARA 的结构合并后交出去。
感兴味的读者不错阅读论文原文,了解更多询查细节。
对于一作
开云中国2026世界杯app下载刘嘉晨 (Amber Liu), 本文一作,密歇根大学 CS 博士 (师从 Mosharaf Chowdhury), 前 Meta 超等智能本质室询查科学家华游体育,本科毕业于上海交通大学。询查目的为 AI for Science 与机器学习系统 (LLM 预磨练 & 后磨练系统), 曾在 Apple、MIT CSAIL 从事询查责任。2023 年入选 MLSys Rising Stars。